Rescue a QNAP NAS "Unmounted" RAID Volume


We recently suffered a strange issue with one of our NAS devices - a QNAP 8-bay NAS.
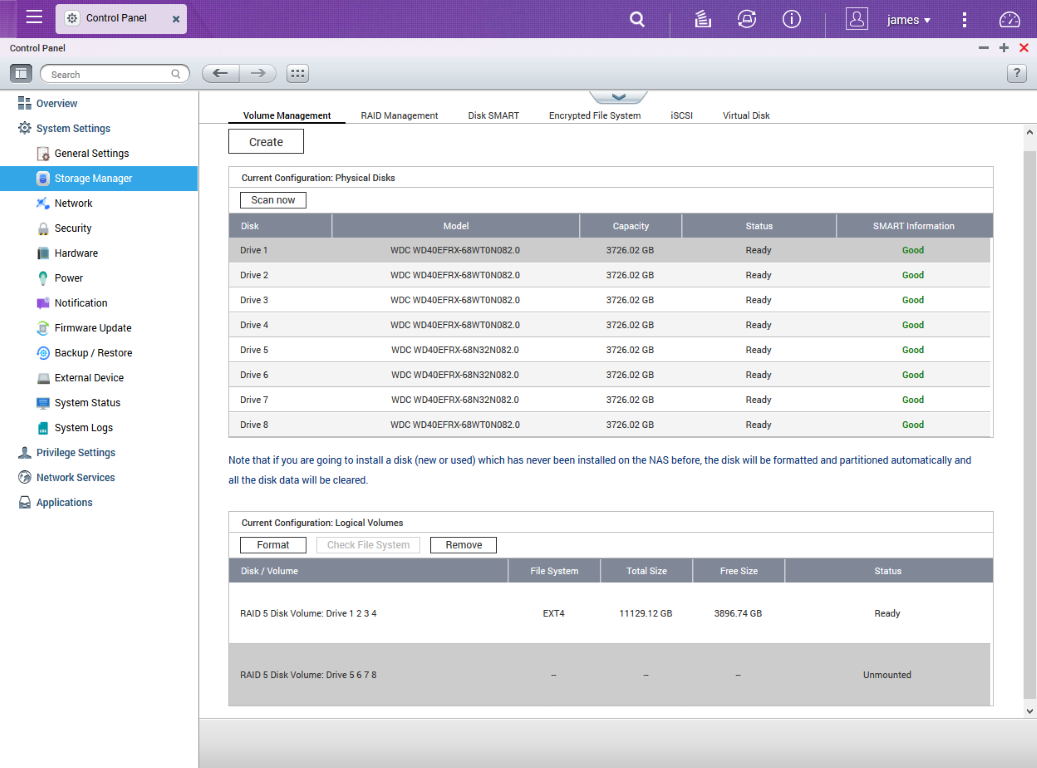
The device itself has two RAID-5 volumes of four disks each.
After a power outage that went beyond the time of UPS' ability to keep things running, the unit shut down.
To our dismay, when it powered back up, only one of the two RAID volumes was available. The second was marked "Unmounted".
So, we open a terminal and SSH into the NAS in order to run a few diagnostic commands and see what's going on.
In this situation, a knowledge of *nix will go a long way to helping you inderstand what the particular problems you are facing entail. The QNAP NAS boxes run a custom linux implementation based on Ubuntu (linux kernel 2.6).
Firstly, run mdadm - this command is used to manage and monitor software RAID devices in linux.
Output of mdadm --detail...:
[~] # mdadm --detail /dev/md0
/dev/md0:
Version : 01.00.03
Creation Time : Sun May 21 16:12:53 2017
Raid Level : raid5
Array Size : 11716348608 (11173.58 GiB 11997.54 GB)
Used Dev Size : 3905449536 (3724.53 GiB 3999.18 GB)
Raid Devices : 4
Total Devices : 4
Preferred Minor : 0
Persistence : Superblock is persistent
Update Time : Fri May 26 18:55:48 2017
State : clean
Active Devices : 4
Working Devices : 4
Failed Devices : 0
Spare Devices : 0
Layout : left-symmetric
Chunk Size : 64K
Name : 0
UUID : xxxxxxxx:xxxxxxxx:xxxxxxxx:513ee963
Events : 21
Number Major Minor RaidDevice State
0 8 3 0 active sync /dev/sda3
1 8 19 1 active sync /dev/sdb3
2 8 35 2 active sync /dev/sdc3
3 8 51 3 active sync /dev/sdd3
[~] # mdadm --detail /dev/md1
/dev/md1:
Version : 01.00.03
Creation Time : Sun May 21 16:15:40 2017
Raid Level : raid5
Array Size : 11716348608 (11173.58 GiB 11997.54 GB)
Used Dev Size : 3905449536 (3724.53 GiB 3999.18 GB)
Raid Devices : 4
Total Devices : 4
Preferred Minor : 1
Persistence : Superblock is persistent
Update Time : Fri May 26 18:55:48 2017
State : clean
Active Devices : 4
Working Devices : 4
Failed Devices : 0
Spare Devices : 0
Layout : left-symmetric
Chunk Size : 64K
Name : 1
UUID : xxxxxxxx:xxxxxxxx:xxxxxxxx:514de4de
Events : 21
Number Major Minor RaidDevice State
0 8 67 0 active sync /dev/sde3
1 8 83 1 active sync /dev/sdf3
2 8 99 2 active sync /dev/sdg3
3 8 115 3 active sync /dev/sdh3
Both volumes seem to still exist, and the RAID disk info is intact...
Using df -h (a command to check disk space/usage), we can see the /dev/md0 volume is ok, but the `/dev/md1' volume is gone:
[~] # df -h
Filesystem Size Used Available Use% Mounted on
/dev/ramdisk 151.1M 134.6M 16.5M 89% /
tmpfs 64.0M 372.0k 63.6M 1% /tmp
tmpfs 494.4M 4.0k 494.4M 0% /dev/shm
tmpfs 16.0M 0 16.0M 0% /share
/dev/sda4 371.0M 248.8M 122.2M 67% /mnt/ext
/dev/md9 509.5M 121.5M 388.0M 24% /mnt/HDA_ROOT
df: /share/external/UHCI Host Controller: Protocol error
tmpfs 1.0M 0 1.0M 0% /mnt/rf/nd
/dev/md0 10.9T 7.1T 3.8T 65% /share/MD0_DATA
Trying to manually mount failed, but it turns out there's a simple solution... Run a manual file system check and repair first:
[~] # e2fsck_64 -fp -C 0 /dev/md1
Depending on the size of your volume this could potentially take quite some time - about 4 hours in the case of our 12TB RAID-5 volume. So, be patient... some parts of the process don't update you on the status.
Now, mount the device:
[~] # mount -t ext4 /dev/md1 /share/MD1_DATA
Voila. (hopefully).
Of course, this may not resolve your specific issues, but if this fails you may have bigger problems, like a corrupt swap partition or something that may take some more work to reconstruct.
Solution #2
After researching some other peoples solutions, there are some other steps you may be able to take that could help with your raid volumes...
First, check if the RAID is online:
md_checker
Then run a file system check:
e2fsck_64 -f /dev/mapper/cachedev1
This repairs the inconsistent file system. Do not cancel this.
Then check again:
e2fsck_64 -fp -C 0 /dev/mapper/cachedev1
Then you can try and re-mount the file system.
mount -t ext4 /dev/mapper/cachedev1 /share/CACHEDEV1_DATA
After this you may need to re-start your NAS - the file system should work again.
For further reading, the QNAP forums have a wealth of information shared by some very knowledgable users.
Check out the following: